Czym jest self w Pythonie: przykłady z życia wzięte

Czym jest self w Pythonie: przykłady z życia wzięte
W tym samouczku dowiesz się, jak zoptymalizować miarę w usłudze LuckyTemplates. Optymalizacja miar w raporcie poprawia wydajność kodów w tworzeniu cennych spostrzeżeń i danych. Dowiesz się również o różnych metodach oceny i sposobach ich zastosowania w celu optymalizacji raportu. Możesz obejrzeć pełny film z tego samouczka na dole tego bloga.
Spis treści
1. Przeanalizuj wydajność kodu
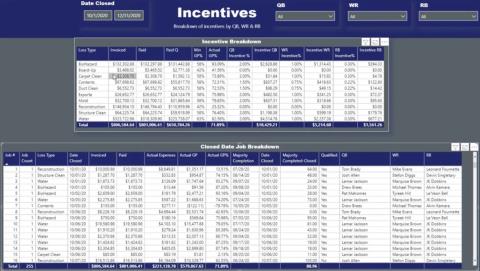
W tym przykładzie musisz zoptymalizować ten raport:

To jest model danych, którego zamierzasz użyć:

Tabela Jobs zawiera wszystkie informacje dotyczące każdego zadania, które zostało wykonane w danym okresie.
Ta tabela jest podstawą wszystkich miar, które zamierzasz zoptymalizować:

Najpierw musisz przetestować wydajność raportu.
Przejdź do zakładki Widok i wybierz Analizator wydajności . Następnie kliknij Rozpocznij nagrywanie i Odśwież wizualizacje . Poczekaj, aż analizator wyrenderuje wizualizację.

Gdy to zrobisz, rozwiń listę Podział zachęt i kliknij Kopiuj zapytanie .

Następnie wybierz Narzędzia zewnętrzne , aby przejść do DAX Studio i spojrzeć na kod wygenerowany przez LuckyTemplates.

Następnie wklej skopiowane zapytanie do obszaru roboczego.

Zmienne w mierze
Pierwsza zmienna to DateClosed , która jest fragmentatorem na pulpicie nawigacyjnym. Wykorzystuje kolumnę z tabeli Fact, aby uzyskać wartości określonych okresów we fragmentatorze.
Następną zmienną jest JobLost , która sprawdza, czy dane Job Lost są fałszywe lub puste.
Ostatnia zmienna to MatrixVisual . To jest serce kodu. Przedstawia kolumnę podsumowania wygenerowaną przez usługę LuckyTemplates w celu wypełnienia wizualizacji macierzy. Grupuje typ utraty pracy w tej macierzy i wprowadza filtry pochodzące z fragmentatorów. Następnie dodaje rozszerzone kolumny.
Gdy kolumna podsumowania zakończy wykonywanie, zobaczysz wyniki w okienku pod kodem.

Usługa LuckyTemplates używa wyniku do wypełnienia wizualizacji macierzy.
Zimna pamięć podręczna dla DAX Studio
Następnie musisz sprawdzić czas wykonania całego kodu. Aby to zrobić, włącz Czasy serwera, a następnie wybierz Wyczyść pamięć podręczną, a następnie uruchom .

Gdy próbujesz zoptymalizować miarę w usłudze LuckyTemplates przy użyciu DAX Studio , lepiej jest działać w scenariuszu z zimną pamięcią podręczną, aby uzyskany czas był prawidłowy. Następnie naciśnij klawisz F5 i poczekaj na zakończenie operacji w zakładce Czasy serwera .
Po zakończeniu możesz zobaczyć, że całkowity czas wykonania wynosi 3,6 sekundy. Spędził większość czasu w silniku formuły i spędził 57 milisekund w silniku pamięci masowej

Możesz również zobaczyć, że znalazł 383 zapytania do silnika pamięci masowej. Spośród wszystkich tych zapytań 327 jest zapisywanych w pamięci, aby można je było ponownie wykorzystać.
2. Analizuj miarę w LuckyTemplates
Następnie musisz zoptymalizować te 3 identyczne miary.

Musisz wyodrębnić te miary do innego pliku i połączyć go z używanym modelem danych.

Następnie uruchom Chronometraż serwera, aby zobaczyć czas potrzebny na 3 miary w wypełnianiu wizualizacji.
Wyniki przebiegu pokazują, że pomiary zajmują 1,85 sekundy, aby pobrać wynik.

Wynik pokazuje tabelę składającą się z 10 wierszy i 3 rozszerzonych kolumn, które należą do podsumowanych kolumn.

Kolumna Typ straty zawiera 10 unikatowych wartości, które kod oblicza w celu uzyskania procentów zachęty.
Czas potrzebny na kod jest wykładniczo długi. To tam i kiedy trzeba je zoptymalizować.
Pomiar% zachęty RB w LuckyTemplates
Jest to miara RB Incentive% w usłudze LuckyTemplates. Jest to jedna z 3 głównych miar użytych w tym przykładzie.

Widać, że próbuje obliczyć procent zachęty.
Ma zmienną JobType, która pobiera wartość Lost Type w bieżącym kontekście filtru. Sprawdza również, czy w bieżącym kontekście filtru widoczna jest tylko jedna wartość. Musisz użyć funkcji , aby za każdym razem, gdy warunek jest spełniony, dawała odpowiedni wynik.
Ten kod środka generuje dużo smaru do silnika, co wydłuża całkowity czas trwania kodu.
Teraz wróć do DAX Studio, aby sprawdzić liczbę zapytań aparatu magazynu generowanych przez miarę.

Jak widać, wykonanie zajęło 600 milisekund, a samo pobranie danych dla 10 wierszy zajęło 43 zapytania do silnika pamięci masowej.
Teraz sprawdź dane, które są żądane z aparatu magazynu. W pierwszym zapytaniu występuje typ utraty pracy i DCOUNT typu utraty pracy.

Następne zapytanie ma Data zamknięcia zadań, która pochodzi z fragmentatora w raporcie.

W trzecim kodzie zobaczysz inny typ utraty pracy z identyfikatorem danych wywołania zwrotnego.

W innym wierszu zobaczysz najważniejsze wiersze kodu.

Pierwszą rzeczą, którą widzisz, jest otrzymanych płatności za zlecenia, zafakturowanych i rzeczywistych wydatków.
Następna jest funkcja WHERE , która określa warunek i odpowiadający mu wynik. Wynik będzie się różnić w zależności od wyboru fragmentatora i instrukcji switch w pomiarze RB Incentive%.
Zauważysz również, że kody w liniach 12 i 14 są takie same.

Jeśli przewiniesz w prawo, zobaczysz, że istnieją wiersze z tymi samymi zapytaniami. Zapytania w wierszach są kierowane przez instrukcję switch w mierze RB Incentive%.

Jeśli wrócisz do miary RB Incentive% w usłudze LuckyTemplates, zobaczysz, ile razy zapytanie jest powtarzane i jak jest to odzwierciedlone w zapytaniach aparatu magazynu.

Logika stojąca za JEŻELI i przełącznikiem
Teraz, aby zrozumieć, dlaczego zapytania są wykonywane wiele razy, musisz zrozumieć logikę funkcji i PRZEŁĄCZ .
Musisz wykonać je oddzielnie w planie zapytań. Ale zanim to zrobisz, upewnij się, że łączysz się z bazą danych i włącz Plan zapytań.
Wykonaj instrukcję SWITCH w planie kwerend. Następnie zaznacz oświadczenie, a następnie naciśnij enter.

Spowoduje to wygenerowanie logicznego planu zapytań z różnymi operacjami.

Następnie wykonaj instrukcję IF , podświetlając ją i naciskając enter.

Widać, że generuje ten sam logiczny plan zapytań.
Dzieje się tak, ponieważ za każdym razem, gdy używasz funkcji PRZEŁĄCZ , silnik wewnętrznie konwertuje tę funkcję na instrukcję JEŻELI . Ale instrukcja SWITCH jest zalecana, ponieważ zwiększa czytelność twojego kodu.
Następnie musisz zrozumieć, w jaki sposób wykonywany jest kod wewnątrz funkcji JEŻELI lub PRZEŁĄCZ .
To jest przykładowy kod zawierający wewnątrz instrukcję SWITCH .

Ma miary dla zysku brutto, całkowitego oszacowania i całkowitego zafakturowanego, które są sumą różnych kolumn. Posiada również funkcję dla typu utraty pracy oraz instrukcje SWITCH i TRUE .
Po wykonaniu tego kodu zobaczysz logikę stojącą za funkcjami.
Pierwsze zapytanie pobiera odrębny typ utraty zadań z tabeli zadań.

Oprócz rodzaju utraty pracy, otrzymuje również sumę szacunkowej liczby miejsc pracy.
Wewnątrz warunku WHERE można również zobaczyć wartości istniejące w kolumnie Typ utraty pracy.

3. Użyj metod oceny kodu
W języku DAX istnieją 3 metody oceniania kodów:
Te metody pomogą zoptymalizować kod lub miarę w usłudze LuckyTemplates.
Pierwsza metoda: ścisła ocena
Poniższy przykład wykorzystuje metodę ścisłej oceny.
Logika, która za tym stoi, jest taka, że jeśli kontekst typu utraty pracy jest równy A, zapewni to zysk brutto. W przeciwnym razie podaje Całkowite oszacowanie. Kod robi to dla każdego wiersza w typie utraty pracy.
Jest to kolejna przykładowa miara w usłudze LuckyTemplates, która używa ścisłej oceny.

Wykonanie tego kodu spowoduje wygenerowanie 5 zapytań do silnika magazynu.

W przypadku Ścisłej oceny kod zapewnia całkowite oszacowanie, jeśli zysk brutto pomnożony przez 1,4 jest większy niż średnie oszacowanie. W przeciwnym razie da zysk brutto.
Korzystanie ze ścisłej oceny powoduje powstanie większej liczby zapytań do mechanizmu pamięci masowej, ponieważ instrukcja IF wielokrotnie sprawdza konkurencję w zakresie zysku brutto i ostatecznie zakłóci wydajność całej operacji.
Druga metoda: chętna ocena
To jest ten sam kod, co w poprzednim przykładzie.
Ale zamiast obliczać miary wewnątrz instrukcji IF , obliczył wszystko w przed RETURN .

Oznacza to, że przed sprawdzeniem wyciągów pobiera wszystkie wartości zysku brutto i oszacowania całkowitego dla wszystkich rodzajów utraty pracy.
Po wykonaniu tego kodu liczba silników pamięci masowej zostanie zmniejszona do 3.

Poprawia wydajność całej operacji.
W pierwszym zapytaniu operacyjnym pobiera typ utraty miejsc pracy oraz sumę szacunkowych miejsc pracy i zysku brutto.

Następne zapytanie pobiera sumę szacunkowych miejsc pracy ze stabilnej oferty pracy. Jest to wykorzystywane do obliczania średniego oszacowania.

Ostatnie zapytanie podaje odrębny typ utraty pracy dla wartości zapisanych w ADDCOLUMNS .

Korzystając z Eager Evaluation, dostajesz wszystko do jednej pamięci podręcznej danych. Dane są również oceniane i iterowane w aparacie formuł. Instrukcja JEŻELI zwróci całkowite oszacowanie lub zysk brutto w zależności od oceny Prawda lub Fałsz.
Chętna ocena nie zawsze jest najlepszą metodą optymalizacji kodów. Ścisła ocena zapewni lepszą wydajność, jeśli masz złożone kody. Wszystko zależy od funkcji, których używasz w kodzie DAX.
Wadą Eager Evaluation jest to, że jeśli utworzysz wartościowe wartości przed instrukcją IF lub SWITCH i użyjesz tych zmiennych wewnątrz instrukcji, które nigdy nie powinny być wykonywane, silnik i tak obliczy te zmienne.
Oto przykład wady:
Idealnie, jeśli typ utraty pracy jest równy A, powinien uzyskać zysk brutto. W przeciwnym razie pobiera Total Estimate.

Ponieważ w kolumnie Typ utraty pracy nie ma żadnej wartości równej A, zawsze powinna ona otrzymać Całkowite oszacowanie. Jednak nadal zapewnia zysk brutto w pamięci podręcznej danych.
Jeśli spojrzysz na pierwsze zapytanie, uzyska ono typ utraty pracy oraz sumę zysku brutto i oszacowania pracy.

W następnym zapytaniu pobiera odrębny typ utraty pracy z tabeli Jobs.

3. metoda: ocena IF.EAGER
Następną metodą jest ocena funkcji IF.EAGER , która replikuje zachowanie Eager Evaluation.
Pozwala napisać kod, który reprezentuje Strict Evaluation i wykonać go z Eager Evaluation.
Jeśli spojrzysz na ten przykładowy kod, okaże się, że jest on taki sam jak kod Strict Evaluation. Jedyna różnica polega na tym, że używa funkcji IF.EAGER zamiast IF .

Przed wykonaniem kodu upewnij się, że łączysz się z modelem LuckyTemplates i włączasz synchronizację serwera. Po zakończeniu naciśnij klawisz F5.
Możesz zobaczyć, że wygenerował 3 zapytania do silnika pamięci masowej.

Pierwsze zapytanie pobiera typ utraty miejsc pracy oraz sumę szacunkowych miejsc pracy i zysku brutto.

Drugie zapytanie pobiera sumę oszacowania miejsc pracy.

Ostatnie zapytanie pobiera odrębny typ utraty zadań z tabeli zadań.

Zauważysz, że wykonał to samo zachowanie, co Eager Evaluation.
Podsumowanie metod oceny
Starając się poprawić wydajność swoich obliczeń, musisz pamiętać o następujących kwestiach:
Pamiętaj jednak, że musisz przetestować te trzy metody, aby dowiedzieć się, co naprawdę najlepiej zastosować w swoim raporcie.
4. Zoptymalizuj miarę w LuckyTemplates
Główną lekcją w tym samouczku jest optymalizacja kodów.
Wróć i spójrz na miarę RB Incentive% , która jest wykonywana przy użyciu ścisłej oceny. Następnie spróbuj ocenić go za pomocą Eager Evaluation.
Zacznij od utworzenia zmiennych i wprowadzenia funkcji RETURN .

Zmień odniesienia do miar za pomocą zmiennych.

Następnie potwierdź pomiar i przejdź do DAX Studio, aby sprawdzić, czy poprawiło to wydajność.
Pokazuje, że całkowity czas wynosi 642 milisekundy, a łączna liczba zapytań do silnika pamięci masowej została zmniejszona do 39.

Teraz utwórz zmienne dla wszystkich danych i zmień wszystkie odniesienia do miar na odpowiadające im zmienne.

Następnie potwierdź pomiar i wykonaj kod w studiu DAX.
Całkowity czas wykonania i łączna liczba zapytań silnika pamięci masowej została zmniejszona odpowiednio z 600 milisekund do 170 milisekund i z 43 zapytań do 15 zapytań.

Możesz również zobaczyć, że nie ma duplikatów. Posiadanie zmiennych w kodzie poprawia ich czytelność i wydajność.
Zaawansowana optymalizacja dla miary w LuckyTemplates
Następnie musisz jeszcze bardziej zoptymalizować swoje kody DAX.
Zamiast używać , użyj funkcji .

HASONEVALUE zlicza liczbę wartości dostępnych w kontekście filtru, co jest bardzo intensywną operacją. Tymczasem ISINSCOPE sprawdza, czy dostarczana kolumna jest używana do grupowania, czy nie.
Po zmianie funkcji zatwierdź pomiar i wykonaj go w DAX Studio.
Jak widać, liczba zapytań do silnika pamięci masowej wynosi teraz 12. Całkowity czas wykonania również wyniósł 105 milisekund.

W drugim zapytaniu zobaczysz identyfikator danych wywołania zwrotnego.

Czasami zdarza się to, gdy używasz SELECTEDVALUE z polem tekstowym. Gdy zobaczysz dane wywołania zwrotnego, aparat magazynu wywołuje aparat formuł, aby pomóc rozwiązać złożoność kodu. To spowalnia działanie twojego środka.
Musisz usunąć dane wywołania zwrotnego, aby uzyskać lepszą wydajność raportu. Aby to zrobić, musisz utworzyć tabelę konfiguracji w modelu danych.
Przejdź do opcji Wprowadź dane i wklej dane. Nazwij tabelę LossTypeConfigTable .

Następnie kliknij Edytuj, aby zmienić typ danych kolumny, którą chcesz zaimportować.
Typ danych identyfikatora typu straty powinien być wartością nauczyciela, aby można go było używać w funkcji SELECTEDVALUE .
Po załadowaniu do modelu utwórz relację między tabelą Jobs a tabelą LossTypeConfigTable na podstawie typu straty.

Po utworzeniu relacji przejdź do tabeli Jobs i dodaj nową kolumnę. Nazwij to Loss ID, a następnie wprowadź formułę.

Użyj funkcji dla tabeli konfiguracji, a następnie wyodrębnij identyfikator typu straty.
Następnie wróć do miary RB Incentive% i odwołaj się do pola numerycznego zamiast do pola tekstowego. Wewnątrz SELECTEDVALUE zastąp typ straty identyfikatorem straty.

Następnie zmodyfikuj wszystkie miary w kodzie. Użyj wartości całkowitej zamiast wartości tekstowych podczas sprawdzania typu pracy.

Po zmianie kodu potwierdź środek i wykonaj go w DAX Studio.
Identyfikator danych wywołania zwrotnego jest eliminowany w zapytaniu, a czas wykonania kodu zostaje skrócony do 93 milisekund.

Miara RB Incentive% jest teraz w pełni zoptymalizowana.
5. Zoptymalizuj inne środki w LuckyTemplates
Należy również zoptymalizować miary WR Incentive% i QB Incentive%.
Skopiuj i wklej dokładny kod użyty w pomiarze RB Incentive%. Następnie wykonaj 3 takty razem.
Całkowity czas wykonania został zoptymalizowany i skrócony z 1855 milisekund do 213 milisekund. Istnieje również tylko 12 zapytań do silnika pamięci masowej.
Pierwsze dwa zapytania tworzą kontekst filtru, a pozostałe reprezentują dokładną liczbę wartości w kolumnie Jobs Loss Type.

Ponieważ wszystkie miary zostały zoptymalizowane, uruchom oryginalny kod i zobacz, jak zmieniła się wydajność. Dane pokazują, że jest teraz obliczany w 1,9 sekundy.

Wydajność całego kodu jest teraz zoptymalizowana, dzięki czemu raport jest szybszy i lepszy.
Optymalizuj funkcje języka DAX dzięki temu nowemu kursowi
Proste transformacje usługi LuckyTemplates w celu uzyskania bardziej zoptymalizowanych danych
Optymalizuj formuły usługi LuckyTemplates przy użyciu zaawansowanego języka DAX
Wniosek
W raportach usługi LuckyTemplates należy zoptymalizować miary, aby zapewnić płynne działanie kodów języka DAX. Poprawia to również ogólną wydajność raportu.
Poznałeś już różne metody optymalizowania miary w usłudze LuckyTemplates i wiesz, jak ocenić, której z nich użyć w zależności od kontekstu raportu.
Czym jest self w Pythonie: przykłady z życia wzięte
Dowiesz się, jak zapisywać i ładować obiekty z pliku .rds w R. Ten blog będzie również omawiał sposób importowania obiektów z R do LuckyTemplates.
Z tego samouczka języka kodowania DAX dowiesz się, jak używać funkcji GENERUJ i jak dynamicznie zmieniać tytuł miary.
W tym samouczku omówiono sposób korzystania z techniki wielowątkowych wizualizacji dynamicznych w celu tworzenia szczegółowych informacji na podstawie dynamicznych wizualizacji danych w raportach.
W tym artykule omówię kontekst filtra. Kontekst filtrowania to jeden z głównych tematów, z którym każdy użytkownik usługi LuckyTemplates powinien zapoznać się na początku.
Chcę pokazać, jak usługa online LuckyTemplates Apps może pomóc w zarządzaniu różnymi raportami i spostrzeżeniami generowanymi z różnych źródeł.
Dowiedz się, jak obliczyć zmiany marży zysku przy użyciu technik, takich jak rozgałęzianie miar i łączenie formuł języka DAX w usłudze LuckyTemplates.
W tym samouczku omówiono idee materializacji pamięci podręcznych danych oraz ich wpływ na wydajność języka DAX w dostarczaniu wyników.
Jeśli do tej pory nadal korzystasz z programu Excel, jest to najlepszy moment, aby zacząć korzystać z usługi LuckyTemplates na potrzeby raportowania biznesowego.
Co to jest brama LuckyTemplates? Wszystko co musisz wiedzieć








